Brain Crew Tech 블로그를 시작합니다
· 약 1분
Where AI really happens — 기술의 본질을 탐구하고, 실제 프로덕트로 만듭니다.
Brain Crew의 엔지니어링·리서치·프로덕트·컬처 이야기를 이곳에 기록합니다.
Where AI really happens — 기술의 본질을 탐구하고, 실제 프로덕트로 만듭니다.
Brain Crew의 엔지니어링·리서치·프로덕트·컬처 이야기를 이곳에 기록합니다.
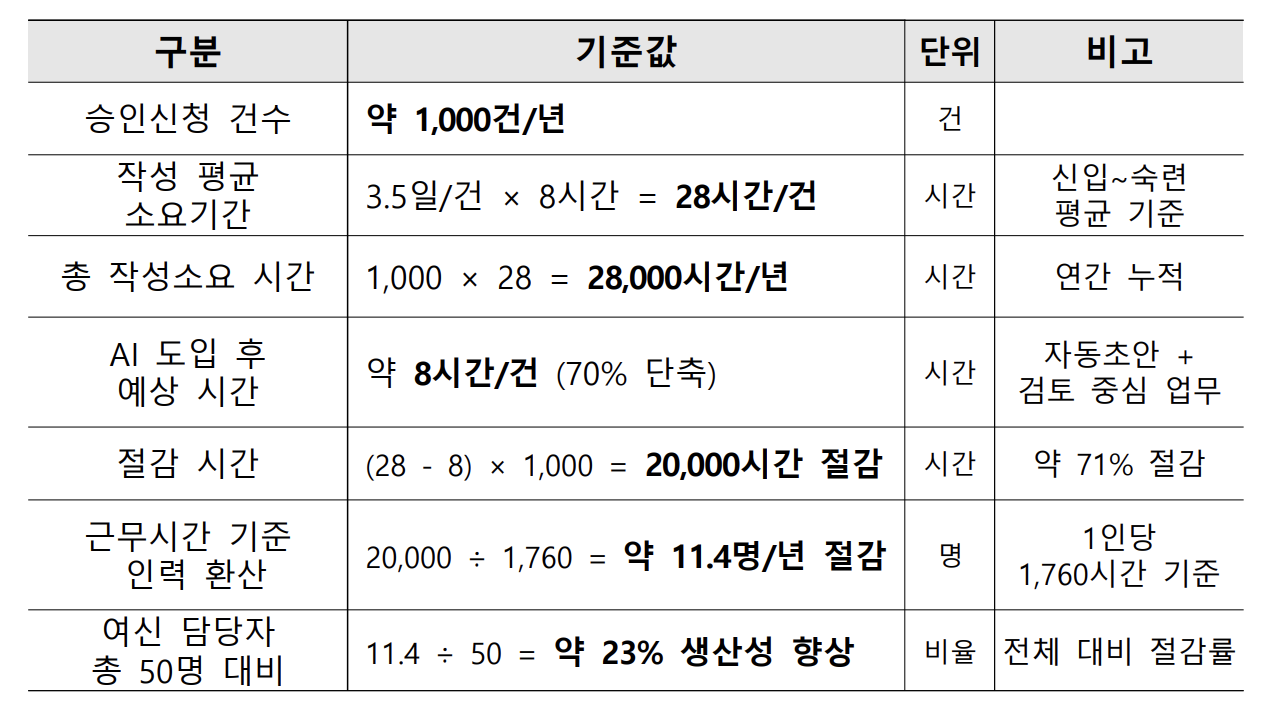
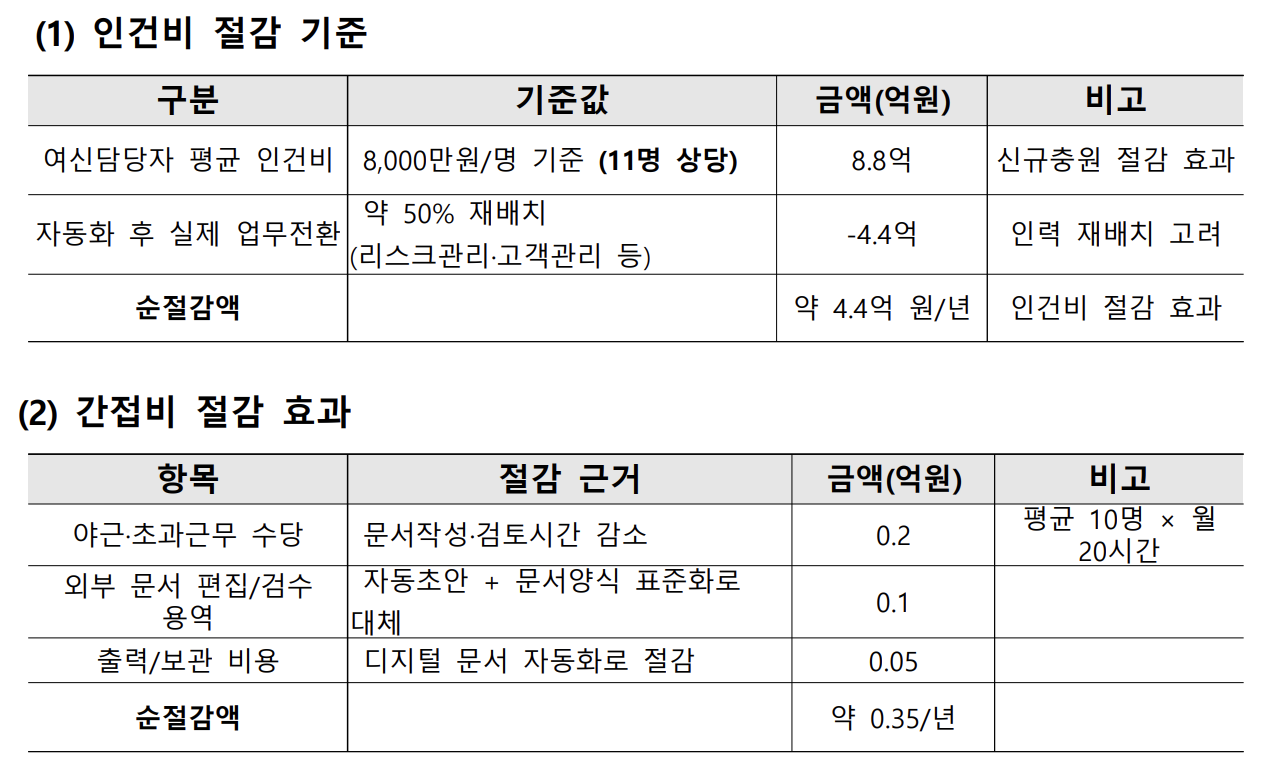
IBK캐피탈의 승인신청서 작성 소요시간을 3.5일에서 1일 이내로 약 70% 단축하고, 반복문서 자동화를 통해 연간 약 4.7억 원 절감 효과를 달성한 AI PoC 프로젝트입니다. 완전폐쇄망(On-Prem) 환경에서 RAG 파이프라인을 구축하며, Table-First 파싱 전략과 HeadingRefiner 기반 청킹으로 금융 문서의 수치 정확성 문제를 해결했습니다.
승인신청서는 IBK캐피탈 영업점이 기업고객과 상담 후 작성하는 비정형 문서입니다. 사업보고서, 감사보고서, 재무제표 등 다양한 문서를 참조하여 9개 섹션을 채워야 하며, 작성과 검토에 많은 시간과 인력이 소요됩니다.
핵심 과제: 생성형 AI 기반 자동화를 통해 문서 작성 효율성과 정확성을 동시에 높이는 것. 특히 완전폐쇄망 환경이라는 제약이 있었습니다.
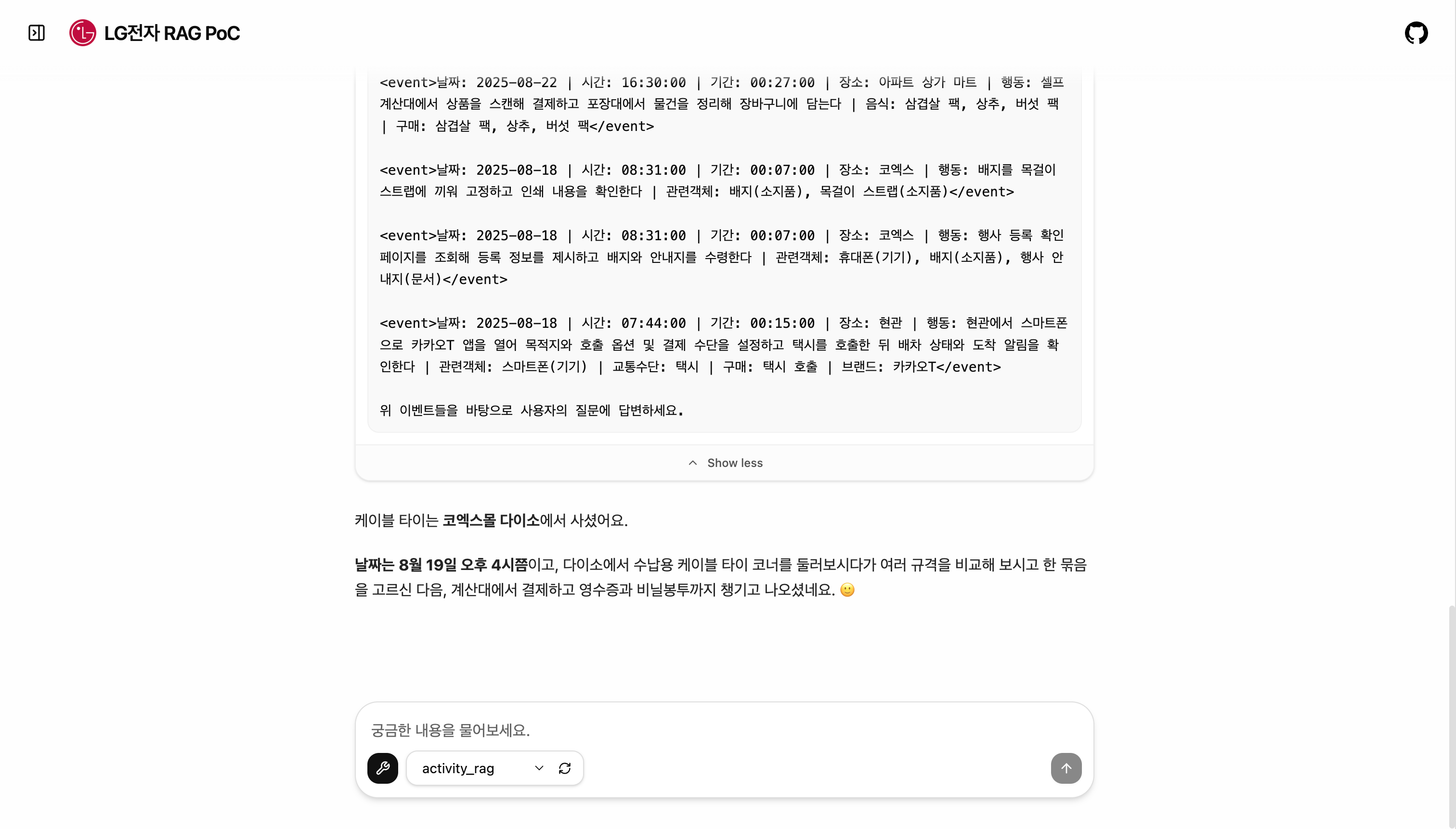
금융 문서에서 가장 중요한 건 수치의 정확성입니다. 단순 PDF 텍스트 추출로는 표 데이터가 깨지는 문제가 있었습니다.
우리가 세운 3가지 원칙:
이를 위해 Table-First Approach를 채택했습니다:
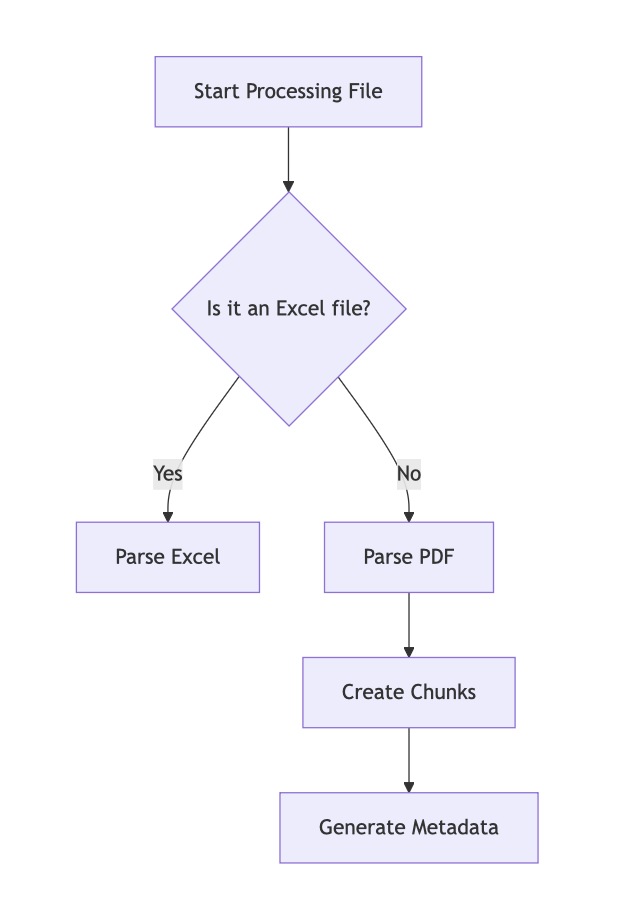
전체 종합 처리 플로우는 다음과 같습니다:
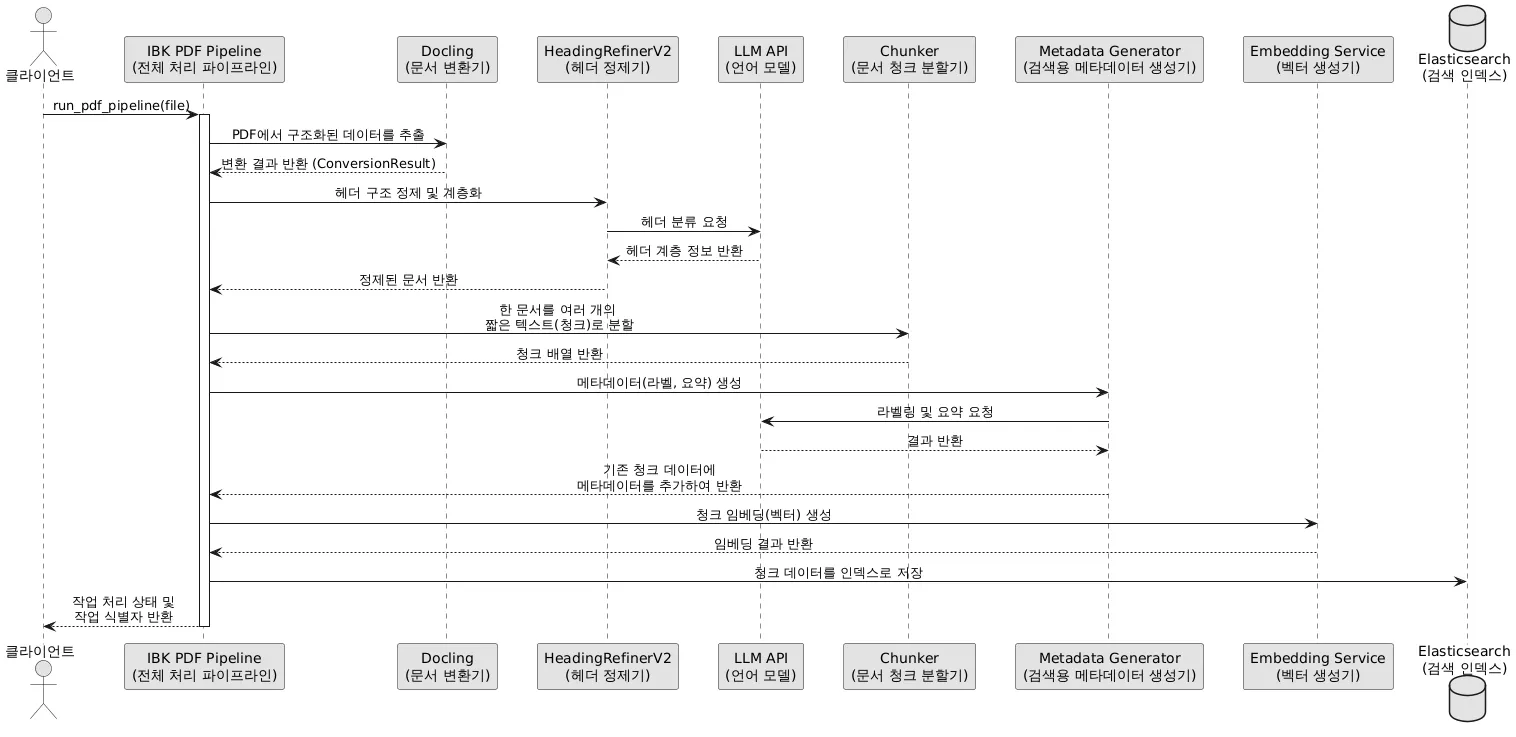
청킹(Chunking) 품질은 heading 추출의 정확도에 직결됩니다. 이를 위해 HeadingRefiner 모듈을 설계했습니다:
이 접근법으로 의미 단락을 더 정확하게 분리할 수 있었고, 최종적으로 의견 생성 품질이 크게 향상되었습니다.
초기 파이프라인은 문서 하나를 처리하는 데 12분 41초가 걸렸습니다. 두 가지 최적화를 동시에 적용했습니다:
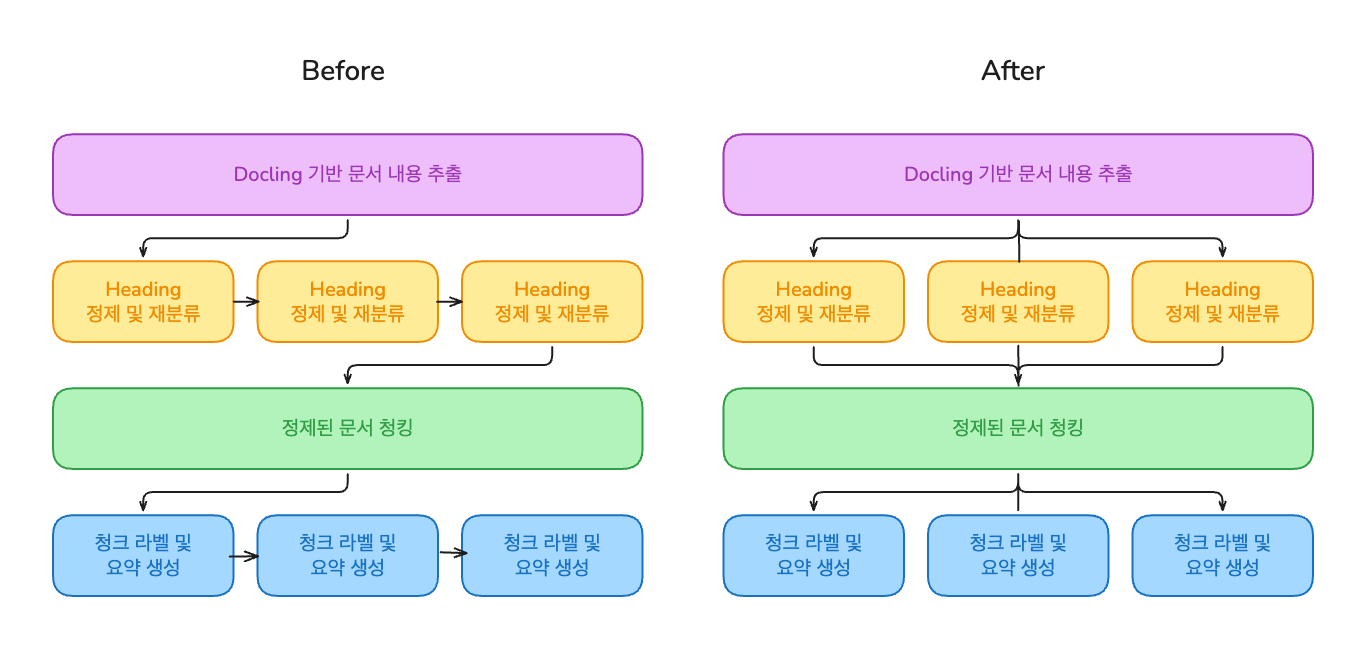
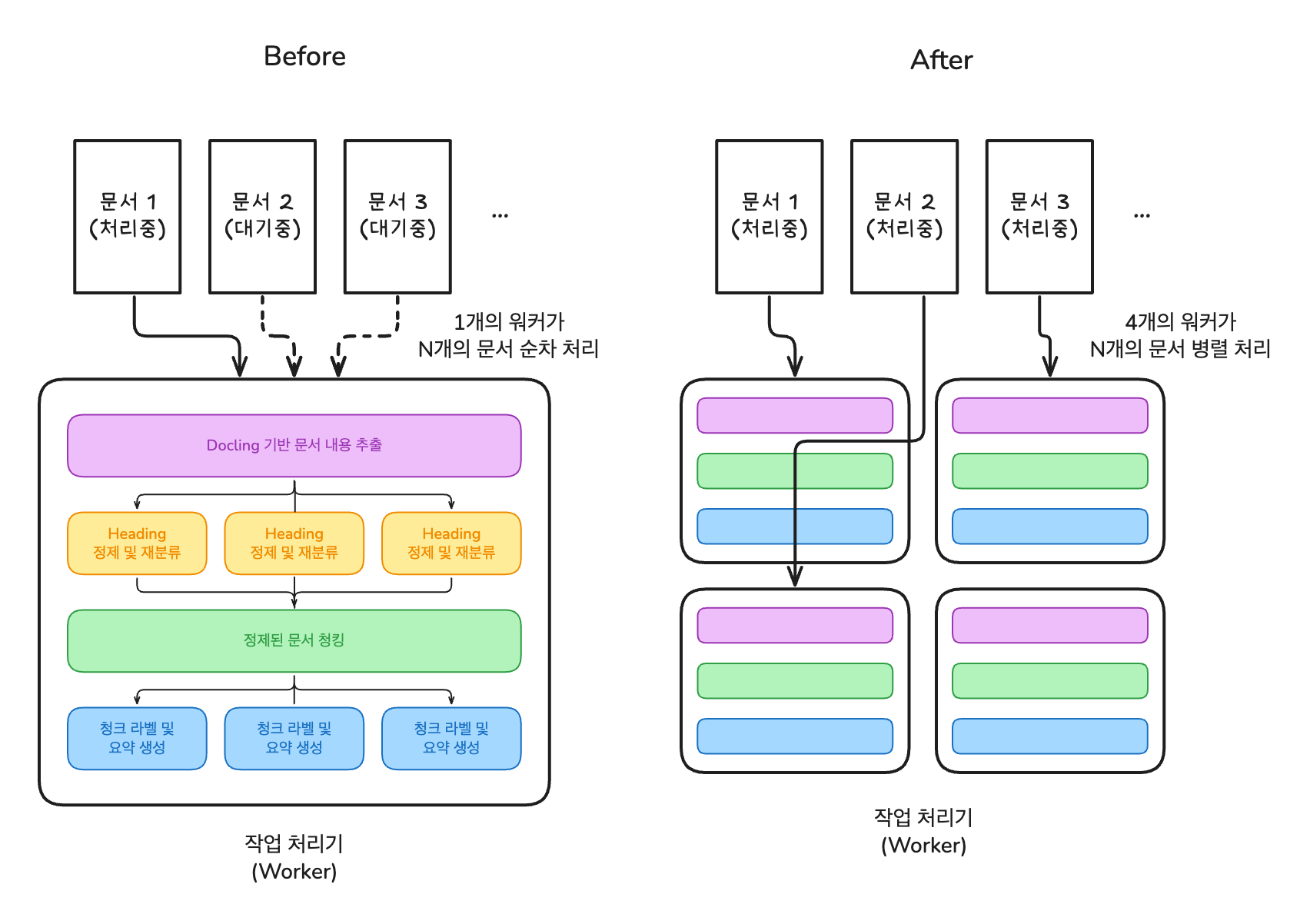
결과: 12분 41초 → 5분 54초 (약 54% 단축)
전처리된 PDF에서 추출된 표 데이터는 형태가 가변적입니다. LLM이 이를 해석할 때 정보 손실을 최소화하기 위해, 컨텍스트로 활용되는 데이터 형태를 Markdown KV(Key-Value) 구조로 변환하여 적용했습니다.
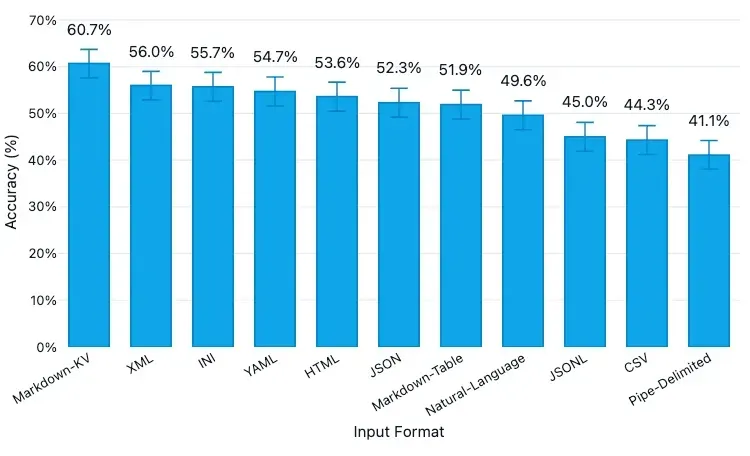
Prompt Engineering을 통해 승인신청서 내부 9개 Section에 대한 개별 응답을 생성하도록 최적화했습니다.
| 항목 | 상세 |
|---|---|
| Web Client | Next.js |
| Backend Server | FastAPI |
| Database | Elasticsearch, Redis |
| 환경 | On-Prem (완전폐쇄망) |
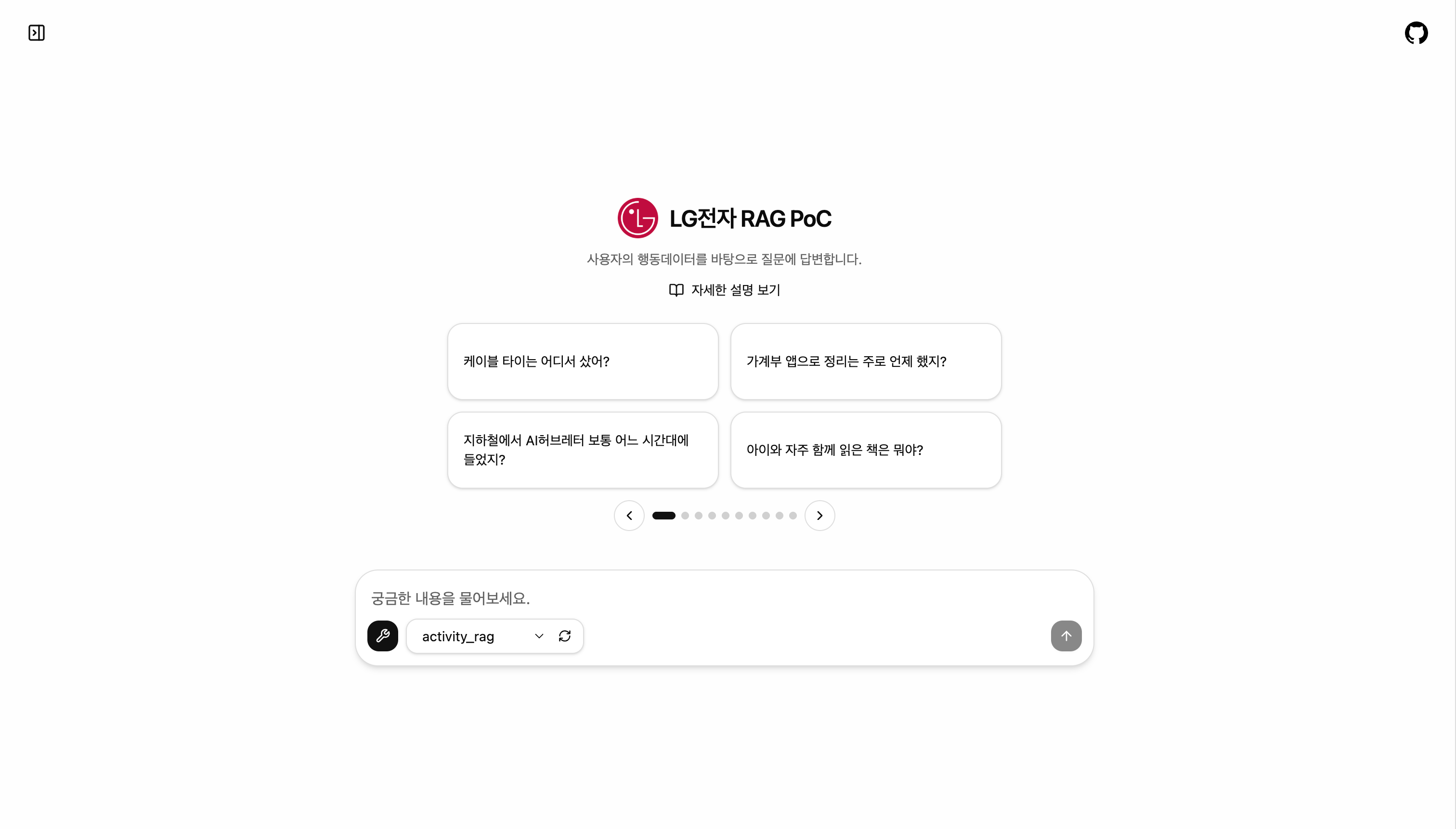
L사 고객의 라이프로그 데이터를 기반으로, "저번주에 커피 몇 번 마셨더라?" 같은 일상적 질문에 정확히 답변하는 AI 어시스턴트를 구축했습니다. 벡터 검색 + 그래프 탐색의 하이브리드 구조로 Context를 20,000개에서 3,000개로 85% 감소시키면서도, 사용자 요구사항 기반 평가셋에서 92%(74/80개) 정확도를 달성했습니다.
사용자가 "캠핑 갔을 때 쓴 버너 뭐였지?"라고 물으면, AI가 복잡한 활동 기록을 연결해서 정확한 답을 찾아줘야 합니다.
단순 키워드 검색으로는 불가능합니다. 시간·장소·활동·브랜드·음식·상황 사이의 복잡한 연결 구조를 AI가 스스로 이해하고 탐색할 수 있어야 합니다.
핵심 과제 4가지:
"캠핑에서 썼던 버너 브랜드"라는 질문을 분해하면:
전통적인 벡터 검색만으로는 이 관계 추론이 불가능합니다. 우리는 모든 활동 데이터를 그래프 형태로 재구성했습니다:
수천~수만 건의 활동 데이터에서 매번 전체 스캔은 비효율적입니다. 벡터 검색(ChromaDB)과 그래프 탐색을 결합한 하이브리드 구조를 설계했습니다.
특히 자연어 시간 표현 자동 해석이 핵심이었습니다:
LLM이 이런 표현을 해석하여 검색 범위를 자동으로 좁혀줍니다.
초기에는 검색 결과로 20,000개의 Context를 LLM에 전달하고 있었습니다. 비용도 높고, 오히려 불필요한 정보가 답변 품질을 떨어뜨리는 문제가 있었습니다.
그래프 탐색을 통해 관련성 높은 Context만 선별하여 3,000개로 85% 감소시켰고, 오히려 답변 일관성이 향상되었습니다. 적은 정보를 정확히 주는 것이 많은 정보를 던지는 것보다 낫다는 교훈을 얻었습니다.
한국어의 다양한 표현 방식이 검색 정확도의 병목이었습니다:
이를 해결하기 위해:
사용자 질문
↓
에이전트 (LangGraph ReAct)
├── Tool 호출 필요 여부 판단
├── query_extraction (활동·시간 관련 내용 추출)
├── GraphRetriever
│ ├── 벡터 검색 (ChromaDB)
│ └── 그래프 탐색 (메타데이터 엣지)
└── 검색 결과 종합
↓
최종 답변 반환
기술 스택: